Rewrite or Refactor? The Decision That Burns Founder Money
I hear this sentence a lot:
"The codebase is a mess. We want to rebuild it from scratch."
Usually, the codebase really is a mess. Features take too long. Bugs keep coming back. Developers are afraid to touch certain parts. The original developer may be gone, the documentation may be weak, and every small change feels more expensive than it should.
At that point, a rewrite sounds reasonable. Start clean. Use a better stack. Fix the architecture. Remove years of bad decisions.
Sometimes that is the right call.
But in many cases, a full rewrite is the most expensive way to avoid understanding the real problem.
The old codebase may be messy, but the mess usually did not appear by accident. It came from rushed deadlines, unclear product decisions, changing requirements, missing tests, customer edge cases, and business rules added over time.
If those problems are not understood, they will follow the team into the new system.
A rewrite can be the right decision. But it should not be the default decision.
Why rewriting feels like the obvious move
A messy codebase creates frustration. Developers complain about it. Founders lose confidence in it. Every delay becomes another proof point that the system is broken.
The emotional appeal of a rewrite is strong because it promises a reset. No legacy decisions. No old hacks. No strange database fields. No files that everyone is afraid to open.
That promise is attractive, especially when the current product feels heavy and unpredictable. It sounds like paying once to remove the pain permanently.
The problem is that a new codebase is only clean because it has not dealt with reality yet.
Early progress in a rewrite can look fast. Login works. The dashboard works. The main screens come together. The team feels good because they are rebuilding the visible parts of the product.
Then the hidden work starts.
A billing edge case appears. A customer-specific export is missing. A report does not match the old system. A permission rule behaves differently. A data migration breaks because old records do not look like the clean schema everyone expected.
This is where rewrite estimates often fall apart.
The hard part is not rebuilding the happy path. The hard part is rediscovering everything the old system learned from production.
The hidden cost of a rewrite
The direct cost of a rewrite is easy to understand: design, development, testing, deployment, and data migration.
The hidden cost is usually more dangerous.
The first hidden cost is the feature freeze. While the team rebuilds the product, the current product often stops improving. New features are delayed because "we'll handle it in the new version." Bugs in the old system become annoying to fix because nobody wants to invest in code that is about to be replaced.
This creates a real business problem. Customers still need fixes. Sales still needs features. Competitors keep shipping. The company feels busy, but the product may not actually improve for users during that period.
The second hidden cost is lost business logic. Old code often contains years of product knowledge. Some of it is ugly, but a lot of it exists for a reason. A strange condition may handle a billing exception. A weird export format may exist because an important customer depends on it. A validation rule may be there because users repeatedly submitted bad data.
I have seen projects where the new version looked cleaner on paper, but months into the rebuild, the team was still finding edge cases the old system handled silently. Not because the old system was good, but because it had already been beaten up by real users.
That knowledge has value.
The third hidden cost is re-debugging. Many bugs in the old system were already discovered, fixed, and paid for. A rewrite can bring similar bugs back in a new form. Permissions are still complicated. Payments are still complicated. Timezones are still complicated. Data imports are still complicated. Search, filtering, reporting, roles, and migrations are still complicated.
Changing the codebase does not remove product complexity. It only moves that complexity into a new implementation.
Why refactoring often wins
Refactoring is less exciting than rewriting, but it is often the better business decision.
A rewrite is one large bet. A refactor is a series of smaller bets.
That matters because smaller bets are easier to control. You can fix one painful area, release it, measure the result, and continue. The product keeps running. Users keep getting improvements. The business does not need to pause while the technical team disappears into a long rebuild.
Refactoring usually makes sense when the product basically works, but specific parts are slowing the team down.
Maybe the frontend is hard to maintain. Maybe the backend has no clear boundaries. Maybe the database structure needs cleanup. Maybe one service is doing too much. Maybe the admin panel has duplicated logic everywhere. Maybe there are no tests around critical flows.
In those cases, replacing the entire system may be unnecessary. The better move is to identify the areas creating the most pain and fix those first.
A good refactor is not "clean code for the sake of clean code." It should have a business reason.
For example, the goal might be to reduce the time it takes to ship new features, make a risky part of the system safer to change, remove duplicated logic that causes bugs, improve performance in a flow users actually use, or make onboarding easier for new developers.
This is the difference between technical cleanup and technical investment.
Cleanup makes developers feel better. Investment makes the product easier and cheaper to run.
If you are deciding what to fix first, the same clarity-before-code mindset applies when you plan a web application build or when timelines slip for reasons that are not purely technical.
The real question is not "rewrite or refactor"
The better question is:
What problem are we actually trying to solve?
If development is slow, the cause might be bad architecture. But it might also be unclear requirements, constant scope changes, weak project management, or developers who do not understand the business domain.
If bugs keep appearing, the cause might be messy code. But it might also be missing tests, poor QA, rushed releases, or unclear acceptance criteria.
If performance is bad, the cause might be the stack. But it might also be bad database queries, missing caching, large payloads, poor frontend rendering, or one badly designed endpoint.
If hiring is difficult, maybe the stack is too old. But maybe the real issue is that the codebase has no documentation, no structure, and no clear ownership.
A rewrite only helps if the old codebase is truly the main blocker.
If the real problem is process, product direction, ownership, or unclear business logic, the rewrite will not fix it. It will only give the team a temporary feeling of progress.
This is where many founders lose money. They choose the biggest technical solution before properly diagnosing the problem.
If the first version became messy because the business kept changing direction, the rewrite will face the same problem.
If the first version became messy because there was no technical leadership, the rewrite will face the same problem.
If the first version became messy because every deadline forced shortcuts, the rewrite will face the same problem.
If the first version became messy because nobody documented product decisions, the rewrite will face the same problem.
New code does not automatically create better decisions.
That is why the technical decision needs to come after diagnosis, not before it.
When a rewrite actually makes sense
A rewrite can be the right decision when the foundation is genuinely wrong.
For example, if the original stack is no longer supported, the main vendor is shutting down, or the technology makes basic development too slow or too risky, rebuilding may be justified.
A rewrite can also make sense when the product has changed so much that the old model no longer fits the business. If every new feature fights against the original architecture, and refactoring would mean replacing most of the core system anyway, a rewrite may be cleaner.
It can also make sense when the product is still small. If the app has limited users, simple flows, and a small amount of data, the risk is much lower. In that case, rebuilding may be faster than carefully untangling a bad foundation.
But even when a rewrite makes sense, it should be treated as a migration, not a fresh side project.
The old system should usually stay live while the new one is built. The new system should be released to a small group first. Critical flows should be compared against the old behavior. Data migration should be tested early, not at the end. The team should document which old behaviors are being kept, changed, or removed.
A rewrite is not just building a cleaner version of the app. It is moving a working business system from one foundation to another.
That is a serious project.
A practical way to decide
A useful rule of thumb:
If a small number of areas create most of the pain, refactor.
If the entire foundation blocks the product's future direction, consider a rewrite.
If the product is making money and users depend on it, be very careful with any plan that stops product progress for months.
"The codebase is messy" is not enough.
You need to know which parts are messy, which parts slow the team down, which parts create the most bugs, which parts are business-critical, and which parts can be replaced safely.
Without that map, a rewrite is mostly a guess.
And expensive guesses are dangerous.
Final thought
A working messy system is still an asset. It may be painful, but it contains real product behavior, real customer knowledge, and real business logic.
A clean unfinished system is not an asset yet.
That does not mean founders should accept bad code forever. Technical debt is real. Slow development is expensive. Fragile systems hurt growth. But the solution should match the actual problem.
Sometimes that means a rewrite.
More often, it means a focused refactor, a better architecture plan, stronger ownership, and fixing the highest-cost parts first.
Before rebuilding your app from scratch, make sure you are not just buying a cleaner version of the same problem.
Ship and fix usually beats start over and pray.
Stuck between rewrite and refactor?
If the codebase is slowing the business but you are not sure what to fix first, the answer is usually triage: map what is actually blocking progress, then refactor or migrate in the smallest steps that keep the product running.
That is the kind of work I do with founders building real products—not disposable demos.
Related posts
The MVP Trap: How Quick and Dirty Code Makes Every Feature Expensive
April 2026•9 min readQuick MVP code feels cheap until every feature ships slower—learn how founders avoid paying twice for the same product.

The Most Expensive Mistake in Software Projects (And Why Teams Miss It)
January 2026•4 min readTeams ship working code that misses the real problem—then pay for rework, politics, and lost months. Align on the problem before you pour concrete into code.
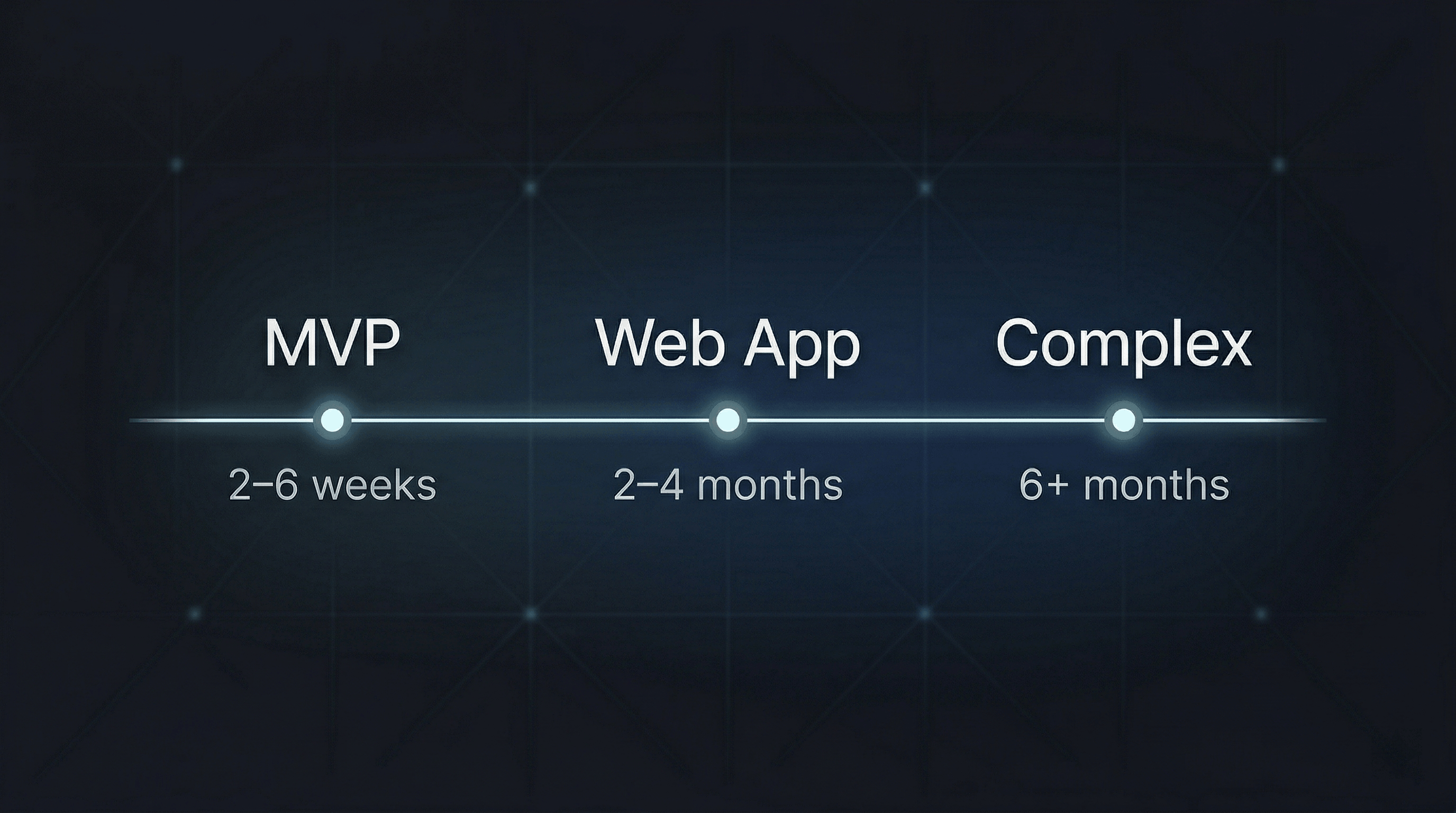
How Long Does It Take to Build a Web Application? (Real Timelines + Hidden Delays Explained)
January 2026•7 min readReal 2026 timelines: MVPs in weeks, solid web apps in months, complex platforms often 6+. Understand what actually stretches calendars—not typing speed—before you commit months of work.
Questions about something you read here, or a project you want to move forward? I work with teams on full-stack builds, AWS and serverless consolidation, migrations, and messy systems.
Contact me